Database connections
Learn how to manage database connections and configure connection pools
Databases can handle a limited number of concurrent connections. Each connection requires RAM, which means that simply increasing the database connection limit without scaling available resources:
- ✔ might allow more processes to connect but
- ✘ significantly affects database performance, and can result in the database being shut down due to exhaustion of system resources
The way your application manages connections also impacts performance. This guide describes how to approach connection management in serverless environments and long-running processes.
This guide focuses on relational databases and how to configure and tune the Prisma ORM connection pool (MongoDB uses the MongoDB driver connection pool).
Long-running processes
Examples of long-running processes include Node.js applications hosted on a service like Heroku or a virtual machine. Use the following checklist as a guide to connection management in long-running environments:
- Configure pool size and timeouts for your driver adapter (defaults and options are adapter-specific)
- Make sure you have one global instance of
PrismaClient
PrismaClient in long-running applications
In long-running applications, we recommend that you:
- ✔ Create one instance of
PrismaClientand re-use it across your application - ✔ Assign
PrismaClientto a global variable in dev environments only to prevent hot reloading from creating new instances
Re-using a single PrismaClient instance
To re-use a single instance, create a module that exports a PrismaClient object:
import { PrismaClient } from "../prisma/generated/client";
let prisma = new PrismaClient();
export default prisma;The object is cached the first time the module is imported. Subsequent requests return the cached object rather than creating a new PrismaClient:
import prisma from "./client";
async function main() {
const allUsers = await prisma.user.findMany();
}
main();You do not have to replicate the example above exactly - the goal is to make sure PrismaClient is cached. For example, you can instantiate PrismaClient in the context object that you pass into an Express app.
Do not explicitly $disconnect()
You do not need to explicitly $disconnect() in the context of a long-running application that is continuously serving requests. Opening a new connection takes time and can slow down your application if you disconnect after each query.
Prevent hot reloading from creating new instances of PrismaClient
Frameworks like Next.js support hot reloading of changed files, which enables you to see changes to your application without restarting. However, if the framework refreshes the module responsible for exporting PrismaClient, this can result in additional, unwanted instances of PrismaClient in a development environment.
As a workaround, you can store PrismaClient as a global variable in development environments only, as global variables are not reloaded:
import { PrismaClient } from "../prisma/generated/client";
const globalForPrisma = globalThis as unknown as { prisma: PrismaClient };
export const prisma = globalForPrisma.prisma || new PrismaClient();
if (process.env.NODE_ENV !== "production") globalForPrisma.prisma = prisma;The way that you import and use Prisma Client does not change:
import { prisma } from "./client";
async function main() {
const allUsers = await prisma.user.findMany();
}
main();Connections Created per CLI Command
In local tests with Postgres, MySQL, and SQLite, each Prisma CLI command typically uses a single connection. The table below shows the ranges observed in these tests. Your environment may produce slightly different results.
| Command | Connections | Description |
|---|---|---|
migrate status | 1 | Checks the status of migrations |
migrate dev | 1–4 | Applies pending migrations in development |
migrate diff | 1–2 | Compares database schema with migration history |
migrate reset | 1–2 | Resets the database and reapplies migrations |
migrate deploy | 1–2 | Applies pending migrations in production |
db pull | 1 | Pulls the database schema into the Prisma schema |
db push | 1–2 | Pushes the Prisma schema to the database |
db execute | 1 | Executes raw SQL commands |
db seed | 1 | Seeds the database with initial data |
Serverless environments (FaaS)
Examples of serverless environments include Node.js functions hosted on AWS Lambda, Vercel or Netlify Functions. Use the following checklist as a guide to connection management in serverless environments:
- Familiarize yourself with the serverless connection management challenge
- Configure pool size and timeouts for your driver adapter (defaults and options are adapter-specific)
- Instantiate
PrismaClientoutside the handler and do not explicitly$disconnect() - Configure function concurrency and handle idle connections
The serverless challenge
In a serverless environment, each function creates its own instance of PrismaClient, and each client instance has its own connection pool.
Consider the following example, where a single AWS Lambda function uses PrismaClient to connect to a database. The connection_limit is 3:
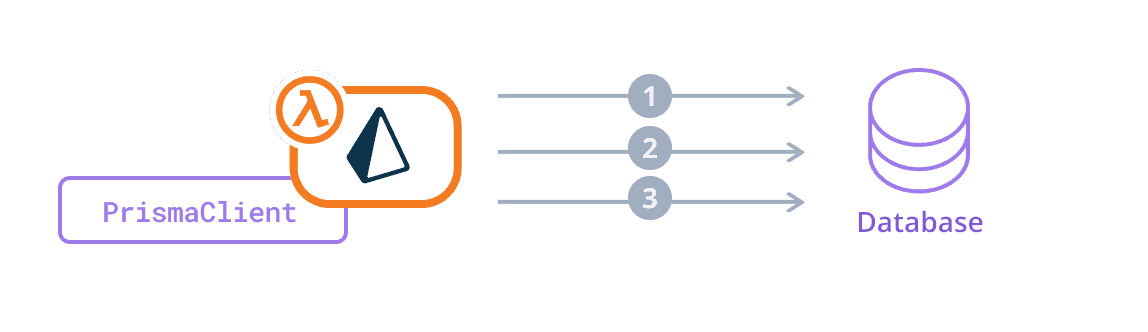
A traffic spike causes AWS Lambda to spawn two additional lambdas to handle the increased load. Each lambda creates an instance of PrismaClient, each with a connection_limit of 3, which results in a maximum of 9 connections to the database:
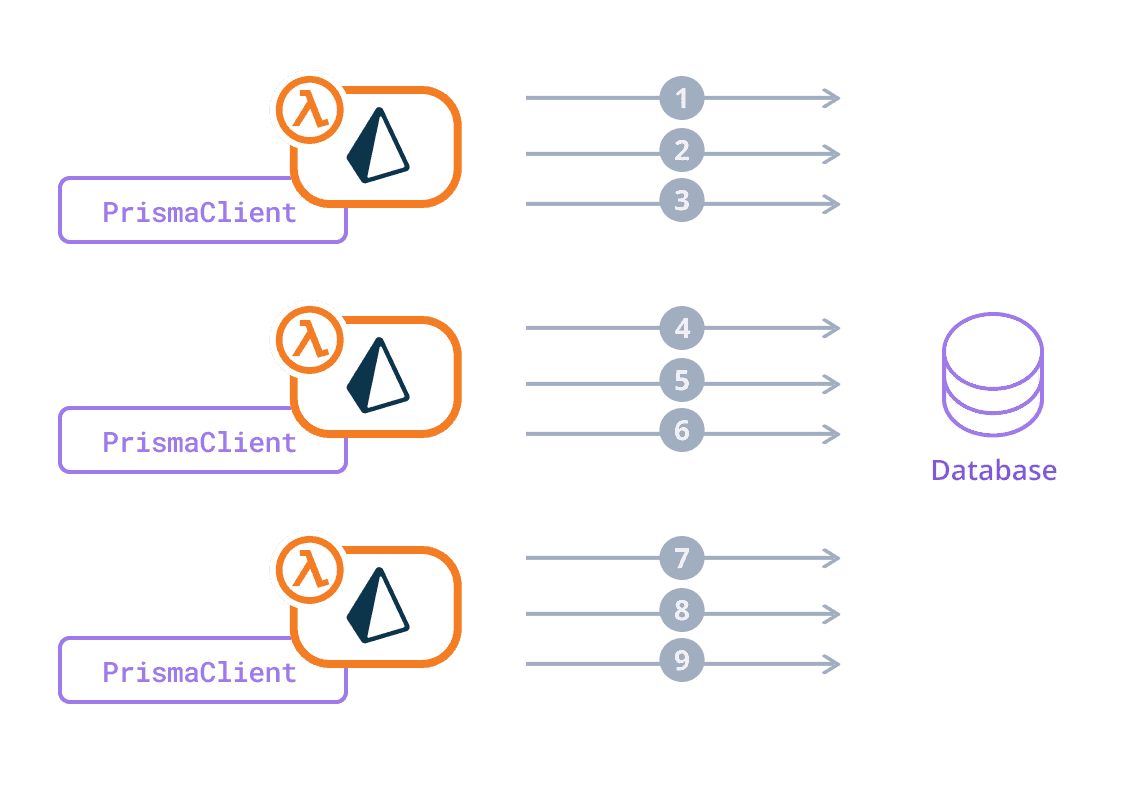
Many concurrent functions responding to a traffic spike 📈 can exhaust the database connection limit very quickly. Furthermore, any functions that are paused keep their connections open by default and block them from being used by another function.
- Configure a small pool size for your driver adapter (adapter-specific; start small when not using a pooler)
- If you need more connections per function, consider using an external connection pooler like PgBouncer
PrismaClient in serverless environments
Instantiate PrismaClient outside the handler
Instantiate PrismaClient outside the scope of the function handler to increase the chances of reuse. As long as the handler remains 'warm' (in use), the connection is potentially reusable:
import { PrismaClient } from "../prisma/generated/client";
const client = new PrismaClient();
export async function handler() {
/* ... */
}Do not explicitly $disconnect()
You do not need to explicitly $disconnect() at the end of a function, as there is a possibility that the container might be reused. Opening a new connection takes time and slows down your function's ability to process requests. In some cases (e.g. Cloudflare Workers), calling $disconnect() when releasing a temporary client is recommended—see the connection management caveat.
Other serverless considerations
Container reuse
There is no guarantee that subsequent nearby invocations of a function will hit the same container - for example, AWS can choose to create a new container at any time.
Code should assume the container to be stateless and create a connection only if it does not exist - Prisma Client JS already implements this logic.
Zombie connections
Containers that are marked "to be removed" and are not being reused still keep a connection open and can stay in that state for some time (unknown and not documented from AWS). This can lead to sub-optimal utilization of the database connections.
A potential solution is to clean up idle connections (serverless-mysql implements this idea, but cannot be used with Prisma ORM).
Concurrency limits
Depending on your serverless concurrency limit (the number of serverless functions running in parallel), you might still exhaust your database's connection limit. This can happen when too many functions are invoked concurrently, each with its own connection pool, which eventually exhausts the database connection limit. To prevent this, you can set your serverless concurrency limit to a number lower than the maximum connection limit of your database divided by the number of connections used by each function invocation (as you might want to be able to connect from another client for other purposes).
Optimizing the connection pool
If Prisma Client cannot obtain a connection from the pool before the adapter's acquire timeout, you will see connection pool timeout exceptions in your log. A connection pool timeout can occur if:
- Many users are accessing your app simultaneously
- You send a large number of queries in parallel (for example, using
await Promise.all())
Pool size, acquire timeout, and other pool behavior are configured per driver adapter—there are no connection URL parameters for these in Prisma ORM v7. See the connection pool reference for each adapter's pool settings (e.g. max, connectionTimeoutMillis for pg) and the underlying driver documentation. Tune the pool so that:
- Your database can support the total number of concurrent connections (pool size × number of instances)
- Timeouts and queue behavior match your workload (e.g. avoid exhausting system resources if the queue grows unbounded)
External connection poolers
Connection poolers like PgBouncer prevent your application from exhausting the database's connection limit.
To keep Prisma Client on the pooled connection while allowing Prisma CLI commands (for example, migrations or introspection) to connect directly, define two environment variables:
# Connection URL to your database using PgBouncer.
DATABASE_URL="postgres://root:password@127.0.0.1:54321/postgres?pgbouncer=true"
# Direct connection URL to the database used for Prisma CLI commands.
DIRECT_URL="postgres://root:password@127.0.0.1:5432/postgres"Configure prisma.config.ts to point to the direct connection string. Prisma CLI commands always read from this configuration.
import "dotenv/config";
import { defineConfig, env } from "prisma/config";
export default defineConfig({
schema: "prisma/schema.prisma",
datasource: {
url: env("DIRECT_URL"),
},
});At runtime, instantiate Prisma Client with a driver adapter (for example, @prisma/adapter-pg) that uses the pooled connection string:
import { PrismaClient } from "../prisma/generated/client";
import { PrismaPg } from "@prisma/adapter-pg";
const adapter = new PrismaPg({ connectionString: process.env.DATABASE_URL });
export const prisma = new PrismaClient({ adapter });PgBouncer
PostgreSQL only supports a certain amount of concurrent connections, and this limit can be reached quite fast when the service usage goes up – especially in serverless environments.
PgBouncer holds a connection pool to the database and proxies incoming client connections by sitting between Prisma Client and the database. This reduces the number of processes a database has to handle at any given time. PgBouncer passes on a limited number of connections to the database and queues additional connections for delivery when connections become available. To use PgBouncer, see Configure Prisma Client with PgBouncer.
AWS RDS Proxy
Due to the way AWS RDS Proxy pins connections, it does not provide any connection pooling benefits when used together with Prisma Client.