What is introspection?
Learn how you can introspect your database to generate a data model into your Prisma schema
You can introspect your database using the Prisma CLI in order to generate the data model in your Prisma schema. The data model is needed to generate Prisma Client.
Introspection is often used to generate an initial version of the data model when adding Prisma ORM to an existing project.
However, it can also be used repeatedly in an application. This is most commonly the case when you're not using Prisma Migrate but perform schema migrations using plain SQL or another migration tool. In that case, you also need to re-introspect your database and subsequently re-generate Prisma Client to reflect the schema changes in your Prisma Client API.
What does introspection do?
Introspection has one main function: Populate your Prisma schema with a data model that reflects the current database schema.
Here's an overview of its main functions on SQL databases:
- Map tables in the database to Prisma models
- Map columns in the database to the fields of Prisma models
- Map indexes in the database to indexes in the Prisma schema
- Map database constraints to attributes or type modifiers in the Prisma schema
On MongoDB, the main functions are the following:
- Map collections in the database to Prisma models. Because a collection in MongoDB doesn't have a predefined structure, Prisma ORM samples the documents in the collection and derives the model structure accordingly (i.e. it maps the fields of the document to the fields of the Prisma model). If embedded types are detected in a collection, these will be mapped to composite types in the Prisma schema.
- Map indexes in the database to indexes in the Prisma schema, if the collection contains at least one document contains a field included in the index
You can learn more about how Prisma ORM maps types from the database to the types available in the Prisma schema on the respective docs page for the data source connector:
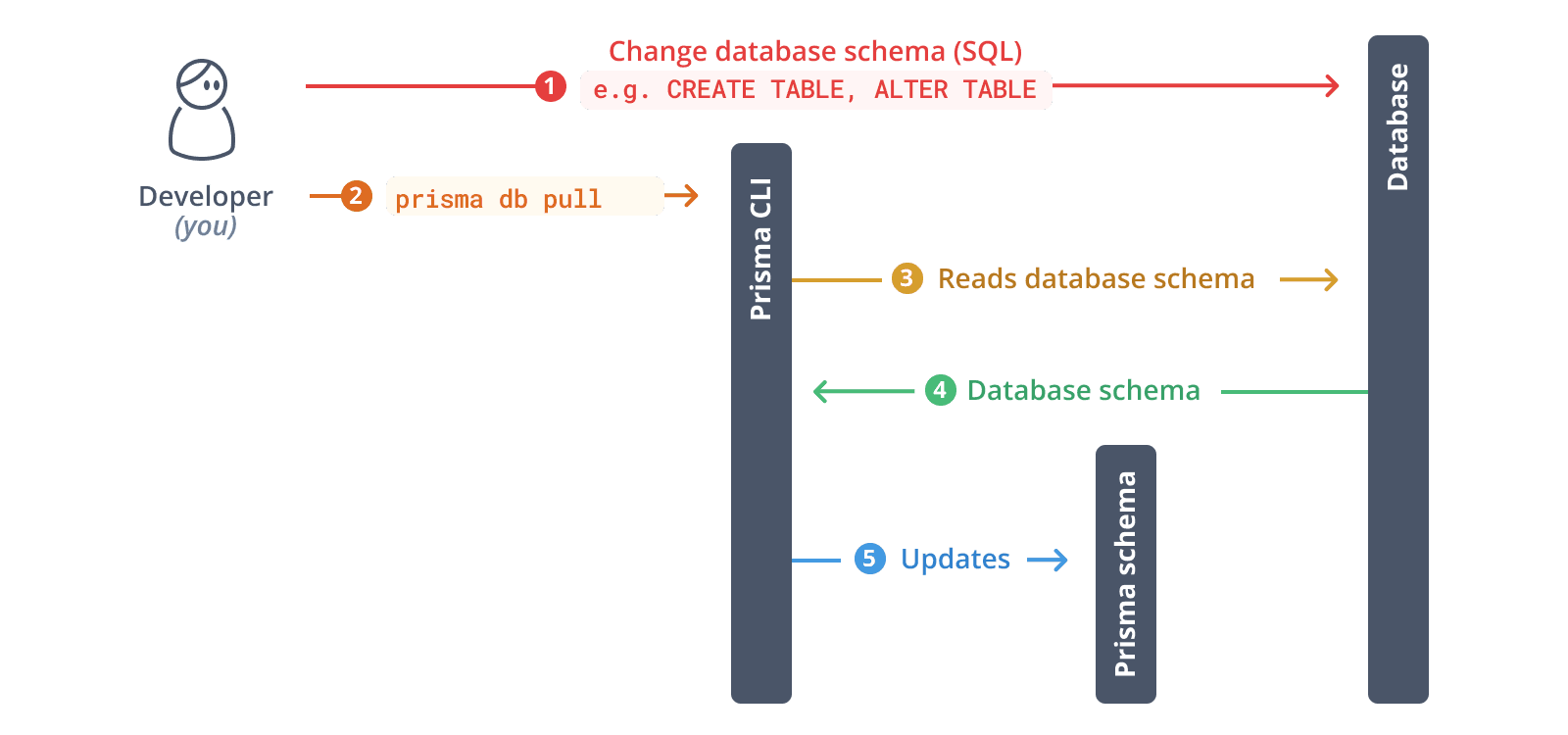
The prisma db pull command
You can introspect your database using the prisma db pull command of the Prisma CLI. Note that using this command requires your connection URL to be set in your Prisma config datasource.
Here's a high-level overview of the steps that prisma db pull performs internally:
- Read the connection URL from the
datasourceconfiguration in the Prisma config - Open a connection to the database
- Introspect database schema (i.e. read tables, columns and other structures ...)
- Transform database schema into Prisma schema data model
- Write data model into Prisma schema or update existing schema
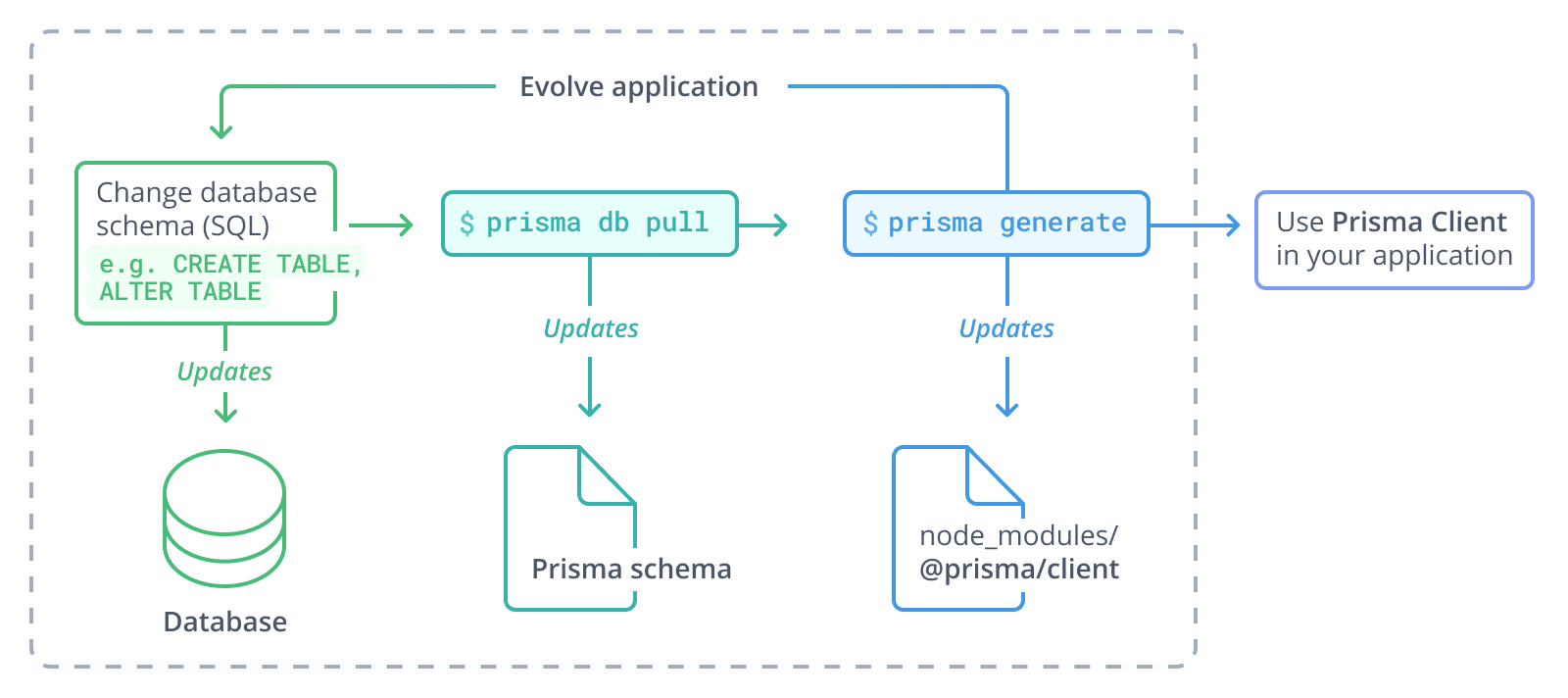
Introspection workflow
The typical workflow for projects that are not using Prisma Migrate, but instead use plain SQL or another migration tool looks as follows:
- Change the database schema (e.g. using plain SQL)
- Run
prisma db pullto update the Prisma schema - Run
prisma generateto update Prisma Client - Use the updated Prisma Client in your application
Note that as you evolve the application, this process can be repeated for an indefinite number of times.
Rules and conventions
Prisma ORM employs a number of conventions for translating a database schema into a data model in the Prisma schema:
Model, field and enum names
Field, model and enum names (identifiers) must start with a letter and generally must only contain underscores, letters and digits. You can find the naming rules and conventions for each of these identifiers on the respective docs page:
The general rule for identifiers is that they need to adhere to this regular expression:
[A-Za-z][A-Za-z0-9_]*Sanitization of invalid characters
Invalid characters are being sanitized during introspection:
- If they appear before a letter in an identifier, they get dropped.
- If they appear after the first letter, they get replaced by an underscore.
Additionally, the transformed name is mapped to the database using @map or @@map to retain the original name.
Consider the following table as an example:
CREATE TABLE "42User" (
_id SERIAL PRIMARY KEY,
_name VARCHAR(255),
two$two INTEGER
);Because the leading 42 in the table name as well as the leading underscores and the $ on the columns are forbidden in Prisma ORM, introspection adds the @map and @@map attributes so that these names adhere to Prisma ORM's naming conventions:
model User {
id Int @id @default(autoincrement()) @map("_id")
name String? @map("_name")
two_two Int? @map("two$two")
@@map("42User")
}Duplicate Identifiers after Sanitization
If sanitization results in duplicate identifiers, no immediate error handling is in place. You get the error later and can manually fix it.
Consider the case of the following two tables:
CREATE TABLE "42User" (
_id SERIAL PRIMARY KEY
);
CREATE TABLE "24User" (
_id SERIAL PRIMARY KEY
);This would result in the following introspection result:
model User {
id Int @id @default(autoincrement()) @map("_id")
@@map("42User")
}
model User {
id Int @id @default(autoincrement()) @map("_id")
@@map("24User")
}Trying to generate your Prisma Client with prisma generate you would get the following error:
npx prisma generate$ npx prisma generate
Error: Schema parsing
error: The model "User" cannot be defined because a model with that name already exists.
*/} schema.prisma:17
|
16 | }
17 | model User {
|
Validation Error Count: 1In this case, you must manually change the name of one of the two generated User models because duplicate model names are not allowed in the Prisma schema.
Order of fields
Introspection lists model fields in the same order as the corresponding table columns in the database.
Order of attributes
Introspection adds attributes in the following order (this order is mirrored by prisma format):
- Block level:
@@id,@@unique,@@index,@@map - Field level :
@id,@unique,@default,@updatedAt,@map,@relation
Relations
Prisma ORM translates foreign keys that are defined on your database tables into relations.
One-to-one relations
Prisma ORM adds a one-to-one relation to your data model when the foreign key on a table has a UNIQUE constraint, e.g.:
CREATE TABLE "User" (
id SERIAL PRIMARY KEY
);
CREATE TABLE "Profile" (
id SERIAL PRIMARY KEY,
"user" integer NOT NULL UNIQUE,
FOREIGN KEY ("user") REFERENCES "User"(id)
);Prisma ORM translates this into the following data model:
model User {
id Int @id @default(autoincrement())
Profile Profile?
}
model Profile {
id Int @id @default(autoincrement())
user Int @unique
User User @relation(fields: [user], references: [id])
}One-to-many relations
By default, Prisma ORM adds a one-to-many relation to your data model for a foreign key it finds in your database schema:
CREATE TABLE "User" (
id SERIAL PRIMARY KEY
);
CREATE TABLE "Post" (
id SERIAL PRIMARY KEY,
"author" integer NOT NULL,
FOREIGN KEY ("author") REFERENCES "User"(id)
);These tables are transformed into the following models:
model User {
id Int @id @default(autoincrement())
Post Post[]
}
model Post {
id Int @id @default(autoincrement())
author Int
User User @relation(fields: [author], references: [id])
}Many-to-many relations
Many-to-many relations are commonly represented as relation tables in relational databases.
Prisma ORM supports two ways for defining many-to-many relations in the Prisma schema:
- Implicit many-to-many relations (Prisma ORM manages the relation table under the hood)
- Explicit many-to-many relations (the relation table is present as a model)
Implicit many-to-many relations are recognized if they adhere to Prisma ORM's conventions for relation tables. Otherwise the relation table is rendered in the Prisma schema as a model (therefore making it an explicit many-to-many relation).
This topic is covered extensively on the docs page about Relations.
Disambiguating relations
Prisma ORM generally omits the name argument on the @relation attribute if it's not needed. Consider the User ↔ Post example from the previous section. The @relation attribute only has the references argument, name is omitted because it's not needed in this case:
model Post {
id Int @id @default(autoincrement())
author Int
User User @relation(fields: [author], references: [id])
}It would be needed if there were two foreign keys defined on the Post table:
CREATE TABLE "User" (
id SERIAL PRIMARY KEY
);
CREATE TABLE "Post" (
id SERIAL PRIMARY KEY,
"author" integer NOT NULL,
"favoritedBy" INTEGER,
FOREIGN KEY ("author") REFERENCES "User"(id),
FOREIGN KEY ("favoritedBy") REFERENCES "User"(id)
);In this case, Prisma ORM needs to disambiguate the relation using a dedicated relation name:
model Post {
id Int @id @default(autoincrement())
author Int
favoritedBy Int?
User_Post_authorToUser User @relation("Post_authorToUser", fields: [author], references: [id])
User_Post_favoritedByToUser User? @relation("Post_favoritedByToUser", fields: [favoritedBy], references: [id])
}
model User {
id Int @id @default(autoincrement())
Post_Post_authorToUser Post[] @relation("Post_authorToUser")
Post_Post_favoritedByToUser Post[] @relation("Post_favoritedByToUser")
}Note that you can rename the Prisma-ORM level relation field to anything you like so that it looks friendlier in the generated Prisma Client API.
Introspection with an existing schema
Running prisma db pull for relational databases with an existing Prisma Schema merges manual changes made to the schema, with changes made in the database. For MongoDB, Introspection for now is meant to be done only once for the initial data model. Running it repeatedly will lead to loss of custom changes, as the ones listed below.
Introspection for relational databases maintains the following manual changes:
- Order of
modelblocks - Order of
enumblocks - Comments
@mapand@@mapattributes@updatedAt@default(cuid())(cuid()is a Prisma-ORM level function)@default(uuid())(uuid()is a Prisma-ORM level function)- Custom
@relationnames
Note: Only relations between models on the database level will be picked up. This means that there must be a foreign key set.
The following properties of the schema are determined by the database:
- Order of fields within
modelblocks - Order of values within
enumblocks
Note: All
enumblocks are listed belowmodelblocks.
Force overwrite
To overwrite manual changes, and generate a schema based solely on the introspected database and ignore any existing Prisma Schema, add the --force flag to the db pull command:
npx prisma db pull --forceUse cases include:
- You want to start from scratch with a schema generated from the underlying database
- You have an invalid schema and must use
--forceto make introspection succeed
Introspecting only a subset of your database schema
Introspecting only a subset of your database schema is not yet officially supported by Prisma ORM.
However, you can achieve this by creating a new database user that only has access to the tables which you'd like to see represented in your Prisma schema, and then perform the introspection using that user. The introspection will then only include the tables the new user has access to.
If your goal is to exclude certain models from the Prisma Client generation, you can add the @@ignore attribute to the model definition in your Prisma schema. Ignored models are excluded from the generated Prisma Client.
Introspection warnings for unsupported features
The Prisma Schema Language (PSL) can express a majority of the database features of the target databases Prisma ORM supports. However, there are features and functionality the Prisma Schema Language still needs to express.
For these features, the Prisma CLI will surface detect usage of the feature in your database and return a warning. The Prisma CLI will also add a comment in the models and fields the features are in use in the Prisma schema. The warnings will also contain a workaround suggestion.
The prisma db pull command will surface the following unsupported features:
- Partitioned tables
- PostgreSQL Row Level Security
- Index sort order,
NULLS FIRST/NULLS LAST - CockroachDB row-level TTL
- Comments
- PostgreSQL deferred constraints
- Check Constraints (MySQL + PostgreSQL)
- Exclusion Constraints
- MongoDB $jsonSchema
- Expression indexes
You can find the list of features we intend to support on GitHub (labeled with topic:database-functionality).
Workaround for introspection warnings for unsupported features
If you are using a relational database and either one of the above features listed in the previous section:
- Create a draft migration:
npx prisma migrate dev --create-only - Add the SQL that adds the feature surfaced in the warnings.
- Apply the draft migration to your database:
npx prisma migrate dev